
Offloading Sentinel's Analysis Pipeline to Local Inference - Conclusions
An overview of what's possible, at what cost, with what hardware.
What each tier of hardware buys
The three realistic hardware paths for a small org like Sentinel.
Best tier — RTX Pro 6000 Blackwell, 96GB. ~$8,500–9,200 new, $7,800–8,200 used. Rental: ~$1/hr on Vast.ai.
What it runs: every model worth running on a single card. gpt-oss-120b at native MXFP4 (66GB weights + headroom). Qwen3.5-27B at BF16. Everything smaller with 90%+ of VRAM unused. Fine-tuning on the 215k pool in reasonable time.
What it costs to actually serve: Part 0's math: a fine-tuned gpt-oss-120b doing per-post analysis projects to ~5,900 analyses/day per card. Sentinel needs ~8,400/day. One card handles 70%, two cards saturate it comfortably.
Mid tier — RTX 4090 / 5090, 24–32GB. ~$1,900–2,700 used RTX 4090 (new is scarce since production ceased). $2,000 MSRP for RTX 5090 when you can find one.
What it runs: anything up to about 20–30B params in quantized form. Qwen3.5-9B, gpt-oss-20b, fine-tuned DeBERTa with room to spare. Can't fit gpt-oss-120b without heavy quantization (which Part 0 established as lossy and not recommended).
Serving capacity: plenty. DeBERTa workloads don't saturate this hardware.
Cheap tier — RTX 3060 12GB / 4060 / older cards. $150–200 used RTX 3060, $350–400 new. $240 RTX 4060.
What it runs: DeBERTa-scale classifiers (435M params, ~1.7GB). Classifier inference and fine-tuning both fit. Any quantized 7B model fits if you want to experiment.
Serving capacity: should be sufficient for the classifier path based on rough math (DeBERTa-large at ~100-150 posts/sec vs. Sentinel's volume fitting easily into an hour of daily compute), but not directly benchmarked.
Context for the numbers: GPU prices across all tiers are up 10–20% in 2026 due to the DRAM shortage. Memory-heavy cards (4090, Pro 6000) are affected most. Rental has stayed stable and is the right move for experiments.
What cannot be done, regardless of hardware
Some things don't unlock by buying better cards. Worth flagging:
- Match gpt-5's full verdict quality locally at gpt-5-mini's cost. No open model at any achievable hardware tier matches gpt-5 on the verification task. gpt-oss-120b is impressive, but at best it gets to "almost as good."
- Generalize across arbitrary subreddits without validation. Part 3's OOD test: F1 dropped from 0.83 to 0.55 moving to unfamiliar communities. This is a deployment-discipline problem : each new community/group of communities needs its own threshold sweep, ideally its own labeled sample. With engineering discipline we could plausibly build threat-specific models per-community, but the effort-to-value ratio is unclear, probably not worth it.
What can be done right now
Different categories of "we have an answer":
Ready to ship today: DeBERTa zero-shot NLI for binary threat triage on threat-heavy subs. Deploy alongside gpt-5-mini in shadow mode first to compare outputs on live data. If the match is acceptable, promote to primary. Operating point to be decided. Runs on any of the three hardware tiers. Saves ~$11k/year on Stage 1 API. Day or two of integration work.
Multi-week project: Train a DeBERTa-scale classifier on the 215k Stage-2 labeled pool. Fits cheap tier hardware. Plausibly beats zero-shot's 0.83 F1 because it's learning gpt-5's actual decision boundary instead of approximating it via entailment.
Other interesting project: Fine-tune a generative model (gpt-oss-120b or Qwen3.5-27B) on the 215k pool for the full structured-output task. This is the real replacement for gpt-5-mini end-to-end. Needs best tier for serving if we commit to gpt-oss-120b.
The training data is already there
One thing that might prove important:
Sentinel's Stage 2 has verified ~215,000 posts since December 2025 (150,881 confirmed threats, 64,929 false positives). Two orders of magnitude more data than threat-bench used.
At 1,900 examples the Part 3 ceiling was real. At 215,000 examples, full fine-tuning becomes viable and the target shifts from "match gpt-5-mini's flag decision" to "match gpt-5's verification".
Every day the pipeline runs, the pool grows. The system gets better over time as a byproduct of doing its normal job, not as a separate annotation budget. Thus, becoming a flywheel.
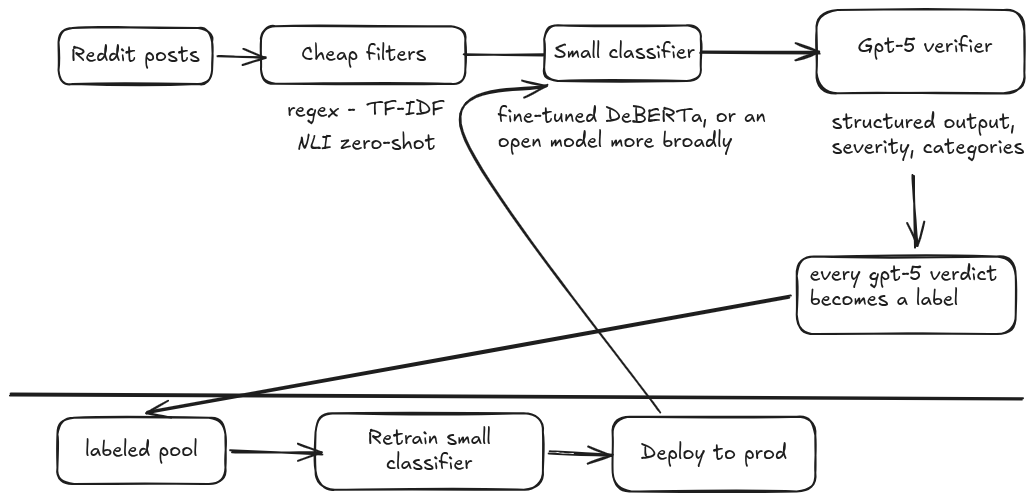
The design, in one diagram
The pipeline we can build with what we have:
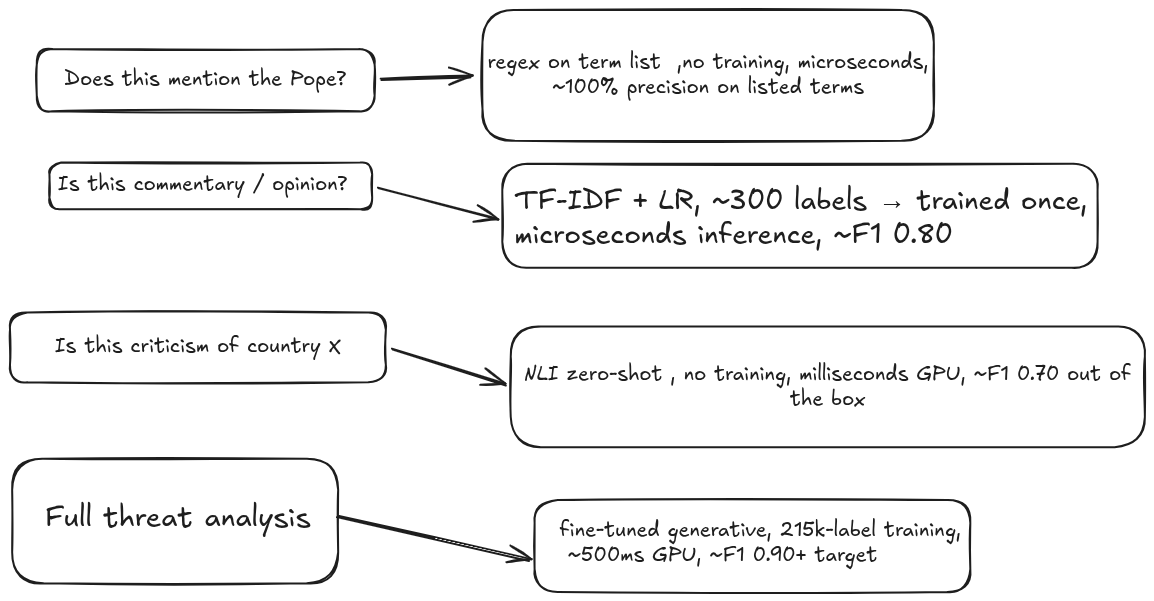
Pick the cheapest tool at each layer that answers the question asked. Regex for named entities. TF-IDF trained on a few hundred labels for topical filters. DeBERTa zero-shot for semantic filters without labels. Fine-tuned generative for full structured output. gpt-5 stays as the verification authority, and its verdicts feed the training set for tomorrow's classifier.
Risks
- If Sentinel expands to many new subreddits, the classifier's OOD fragility matters more. Each new community needs its own threshold sweep and ideally its own labeled sample.
- If gpt-5's verdicts are systematically biased in some direction, the flywheel amplifies that bias. The distilled classifier inherits whatever gpt-5 gets wrong.
- If Stage 2 volume has to stay bounded for cost reasons, the classifier's flag rate matters as much as its F1.
Why this matters for small orgs
Small orgs monitoring large volumes face the same shape: running a frontier API on every input is expensive; running a smaller local model on every input is cheap if something reasonable exists at their scale. The classifier path is that something reasonable, and the flywheel means you don't need to fund a separate annotation campaign: verification API calls are the labels.
For Sentinel specifically: even $150–400 of consumer hardware might handle binary triage at reasonable volume, with the $8k card only necessary if we commit to running gpt-oss-120b locally for the full schema task. The hardware question is downstream of the product question.
Important
Part 0 recommended an RTX Pro 6000 Blackwell as the first purchase. That's still correct if we commit to the full generative replacement path. After Parts 2–3 I think the more important question is whether we need to. The classifier path replaces binary triage on any cheap card. The RTX Pro 6000 only earns itself if we decide gpt-oss-120b fine-tuned is the future of Stage 1, and we can answer that question with a one-week rental experiment before spending $8k.